Credit Card
Explore
MAR 15, 2023
How We Built a Modern Data Platform at Gemini

- Our Analytics team built a modern data platform using Databricks Lakehouse to automate and simplify data processes, providing a foundation for future data innovations.
- The Gemini Dynamic Data Load (GDDL) architecture was built to manage a growing data landscape and provide self-service capabilities by leveraging the powerful features of Databricks and AWS.
- This architecture ensures automatic scaling, structural evolution, and efficient replication and loading of data into our Lakehouse within defined SLAs.
The Gemini Analytics team strives to automate, simplify, and build processes that provide a strong foundation for future data innovations. Contained within the Analytics team is the Data Engineering team, which is specifically tasked with managing the ever-expanding data landscape to deliver advanced data capabilities, while minimizing costs. This has led to a focus on simplification and automation, which is a continuous process that evolves over time and adapts to technical and business needs.
Problem Overview
As data becomes increasingly vital to organizations, data engineers, machine learning engineers, and analytics engineers all rely on the work of data engineering and platform teams to deliver high-quality data. These teams face a range of tasks, including:
- Ingesting new data into the system at various intervals, including streaming data;
- Validating and formatting data to meet the needs of different sizes and time periods;
- Updating and managing data structures, regardless of whether the data and platform are centralized or distributed;
- Minimizing infrastructure costs while maintaining performance and reliability.
As the number of data-related requests continues to rise, managing the resulting growth in data requires a constant influx of resources, time, and effort. The sheer scale of this data behemoth demands a rigorous approach to ensure that data is accurate, accessible, and secure.
Business requirements and engineering challenges have driven us to develop a robust solution that addresses these needs. Our Gemini Dynamic Data Load (GDDL) architecture is designed to auto-scale, structurally evolve, unify data, and provide self-service capabilities. This is achieved by leveraging the powerful features of and Amazon Web Services (AWS).
Solution Overview
In the Gemini data universe, data is sourced from a variety of systems, including Online Transaction Processing (OLTP) systems, message buses, No-SQL databases, API ingestions, and external third party data captures. This blog post focuses specifically on our GDDL solution which was developed to replicate and ingest data from the core OLTP systems housing thousands of tables.
To understand our solution, it's important to first understand our overall data processes. From a data architecture perspective, we replicate historical and incremental Change Data Capture (CDC) data from different source systems to our Amazon Simple Storage Service (S3) bucket. This data is then unified in the GDDL architecture to meet critical business needs and enable downstream reporting.
The GDDL architecture
The GDDL architecture serves a range of functions that work together and enable us to parse and deliver relevant data quickly and accurately. These functions include:
- Capturing changes made to data in a database and delivering them to a file system (S3) in real time or near real time;
- Loading incremental CDC data into one table and replicating transactional database data into a separate table in chronological order based on its nature and size, using either a pre-defined schedule or a custom schedule;
- Leveraging optimal compute that ingests tables based on their sizes (small, medium, and large tables);
- Onboarding new datasets or tables dynamically with minimal ad-hoc development;
- Structurally evolving models for data migrations (e.g. the addition or removal of columns at the source database);
- Establishing service-level agreements (SLAs) for specific tables by optimizing compute-level performance and providing flexibility for ad-hoc requests.
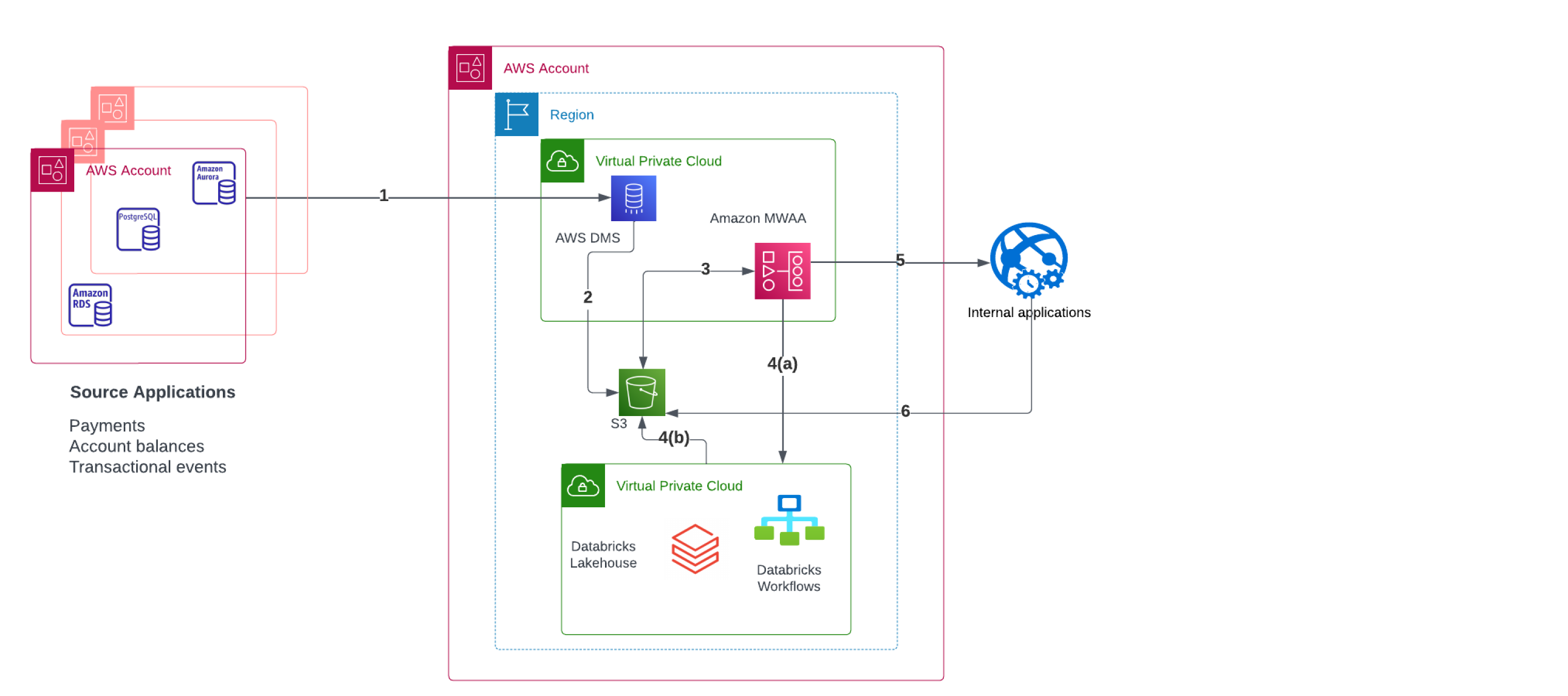 Figure 1: Gemini’s Cloud Architecture for Data Ingestion. This diagram illustrates the high-level solution architecture.
Figure 1: Gemini’s Cloud Architecture for Data Ingestion. This diagram illustrates the high-level solution architecture.
Step 1: Database Migration Service (AWS DMS) streams data from Relational Database Service (Amazon RDS) and Aurora (Amazon Aurora) hosted in different AWS accounts.
Step 2: DMS delivers streaming data to Amazon S3.
Step 3: Amazon Managed Workflows for Apache Airflow (Amazon MWAA) tasks run in specific schedules and check for the availability of data on Amazon S3.
Step 4(a): Scheduled tasks in Amazon MWAA invoke Databricks Workflows.
Step 4(b): Databricks Jobs as part of Databricks Workflow loads data into the Lakehouse on Amazon S3.
Step 5: Amazon MWAA tasks invoke internal ETL jobs for downstreams.
Step 6: Downstream ETL jobs consume data from Lakehouse on Amazon S3.
Architecture Guidelines
Below are the guiding principles we followed during the development of GDDL:
- Unified Modular Code: Modularization and parameterization were used to arrive at a unified code that can easily be enhanced and extended.
- Auto-Concurrent Data Loads: Ingest thousands of tables concurrently with zero manual intervention or auto-throttled invocations.
- Job Maintainability/Dependency Management: An orchestration mechanism and dependency management were built into the architecture to facilitate easier maintenance and re-run of jobs by on-call engineers and subject matter experts (SMEs).
- Streaming vs. Batch Fashion: The code architecture is easily adaptable to real-time or near-real-time streaming needs, with simple configuration-driven code changes.
- Service Driven: Jobs were exposed as a service through a service-oriented architecture, enabling internal non-data teams and engineers, such as Marketing, to set dependencies on data jobs.
Core Architecture and Implementation
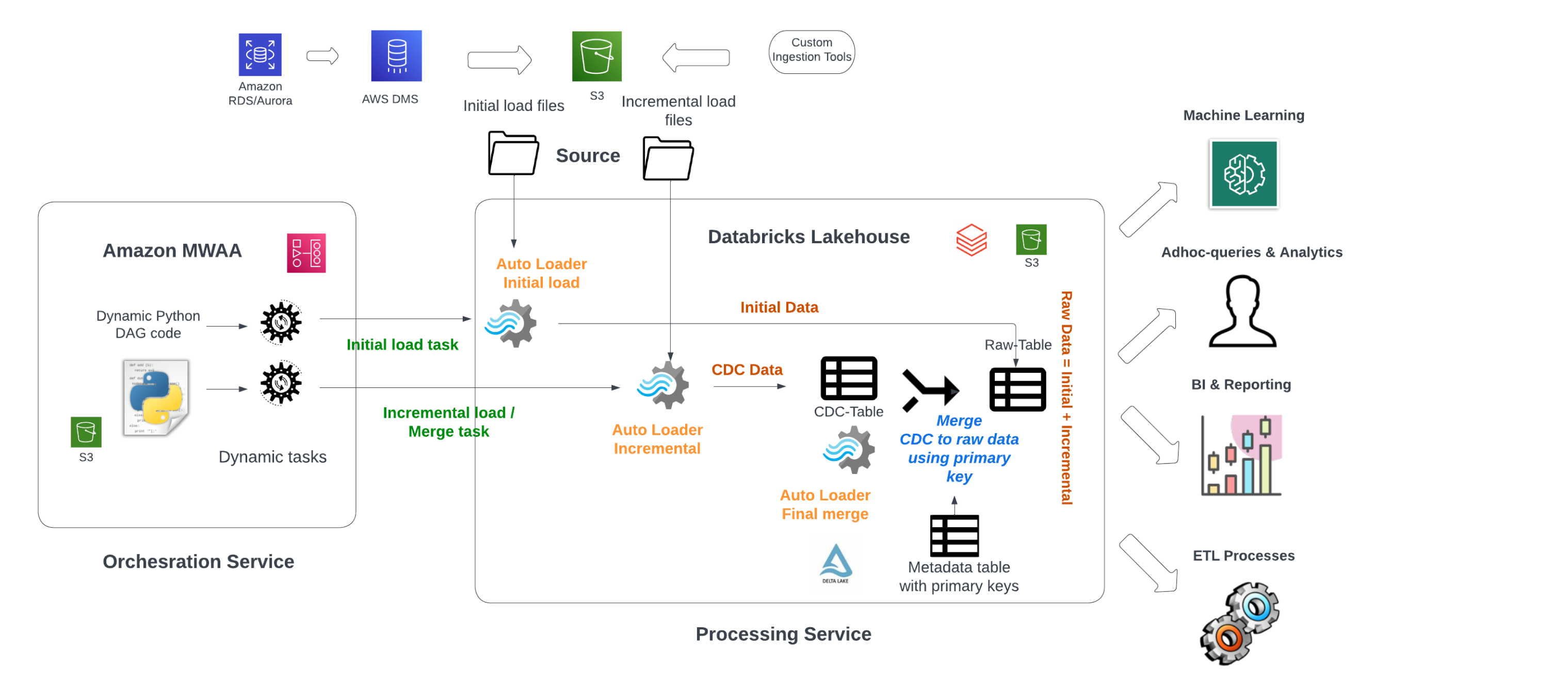 Figure 2: GDDL Architecture has three components detailed in the sections below.
Figure 2: GDDL Architecture has three components detailed in the sections below.
1. Source
- Data is ingested to S3 in Parquet format using third-party data-ingestion tools or cloud-native services like .
- Custom ingestion tools and the database migration service load one-time initial data and stream incremental CDC data on a specific frequency from the replication logs of transactional databases with different schema types.
- Predictive analytics and Business Intelligence (BI) reporting require CDC data and full transactional data to be preserved in separate delta tables. These requirements in turn demand schema synthesis and data unification so that the destination delta table reflects the true replica of the source for downstream consumption.
2. Processing Service
- Initial and incremental CDC data are unified into raw delta tables using Structured Spark streaming by leveraging Auto Loader capabilities to meet batch and streaming needs.
- The processing service layer aims to unify data for user consumption and downstream processing.
- Our Spark jobs are designed to be parameterized using table name, schema name, and a flag indicating whether a full refresh is required. When an incoming Airflow API request is received, PySpark code reads these parameters and constructs the S3 directory location. This information is then passed to the Auto Loader component of the PySpark code, which processes the existing or new files as they arrive into the S3 directory.
- Our processing service replicates the raw data to delta tables that correspond to the bronze layer of the . This ensures that the data is transformed and stored in a way that facilitates downstream analysis and reporting.
3. Orchestration Service
- Our solution generates dynamic Airflow Directed Acyclic Graphs (DAGs) and tasks using Python code on MWAA, which leverages metadata managed in S3, including table name, primary key, and table size. This approach enables us to dynamically add tables, datasets, and job invocations in an elastic manner, by invoking corresponding Databricks Workflows.
As we outline above, DMS acts as the cardinal replication service in our architecture. We will now hone in on how we built out our processing and orchestration service.
There are two stages involved in the processing service to arrive at the final table:
- Stage1 → Initial Load/Main Table: Our Auto Loader code merges newly arrived data into the final raw delta table using its primary key. If this is the first time the data is being loaded, the code creates the main table and writes the files to the final raw delta table location. This approach ensures that the data is accurately and efficiently loaded into the system.
- Stage2 → Incremental Load/Incremental Table: Our Auto Loader appends the incoming new CDC data to the incremental delta table location and merges it with the final raw delta table.
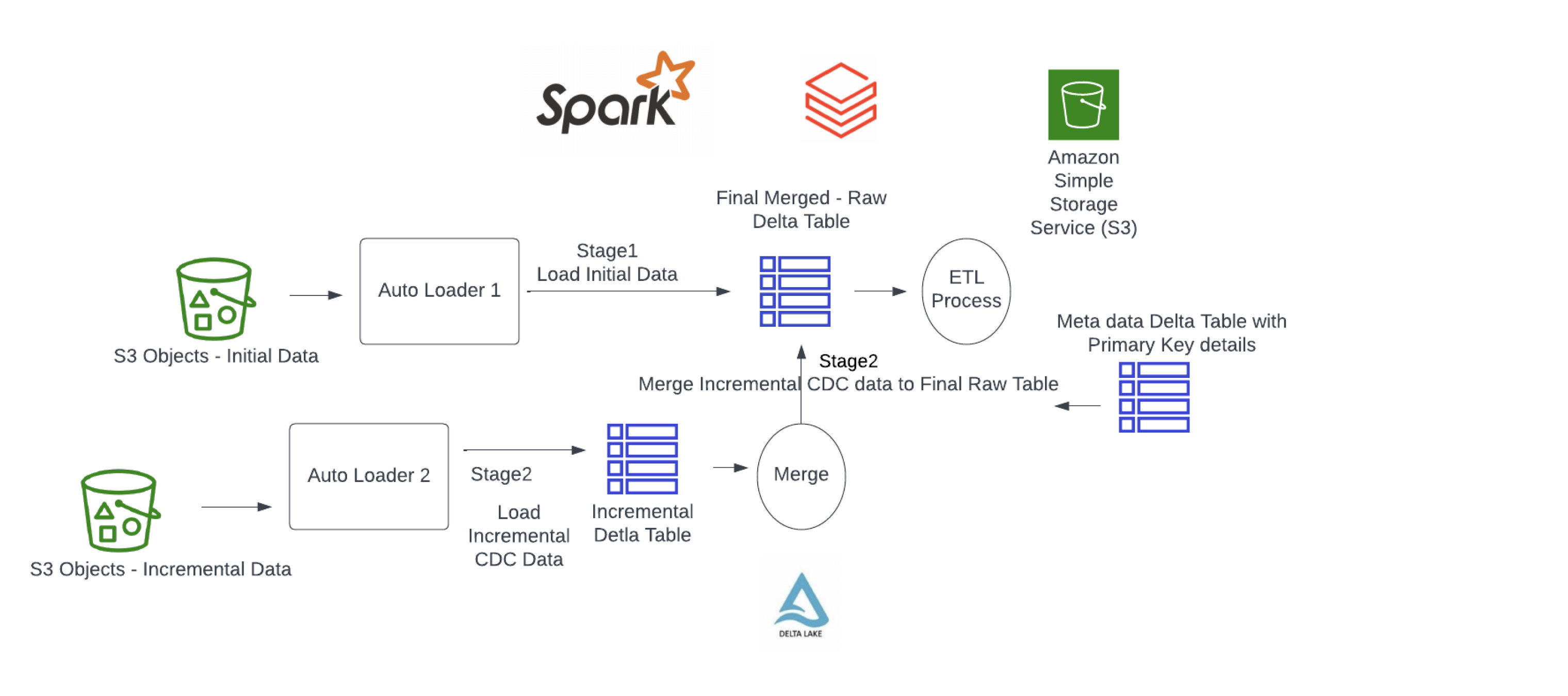 Figure 3: Leveraging Databricks Auto Loader to simplify ingestion of change data.
Figure 3: Leveraging Databricks Auto Loader to simplify ingestion of change data.
We noticed that the streaming data can have multiple incremental CDC events for the same primary key for a specific time frame, since multiple events could happen for the same primary key. In order to execute a successful merge, the data team used a window function at the micro batch level to sort the records using the date column in the metadata delta table, pick up the latest row, and perform a merge. Please refer to the Python pseudo code below that takes care of schema evolution and data merges. Also refer to .
def upsert_query_constructor(self):
# Constructs string that is pre populated for on clause.
on_clause_string=' and '.join(on_clause_constructor(self))
merge_query = f"""
MERGE INTO dms_{self.dataset}.{self.table} AS t
USING updates AS s
ON {on_clause_string}
WHEN MATCHED AND s.transact_seq > t.transact_seq
AND Op in ('U', 'I') THEN UPDATE SET *
WHEN MATCHED AND s.transact_seq > t.transact_seq
AND Op = 'D' THEN DELETE
WHEN NOT MATCHED AND Op in ('U', 'I') THEN INSERT *
"""
return merge_query
def upsertToDeltaDF(microBatchOutputDF, batchId):
windowSpec = (
Window
.partitionBy(self.primary_keys)
.orderBy(col('transact_seq')
.desc()
)
dframe_with_rank = (
microBatchOutputDF
.withColumn("dense_rank", dense_rank().over(windowSpec))
)
microBatchOutputDframe_rank = (
dframe_with_rank
.filter(dframe_with_rank.dense_rank == 1)
)
microBatchOutputDframe_rank.createOrReplaceTempView("updates")
microBatchOutputDframe_rank._jdf.sparkSession().sql(upsert_query_constructor(self))
# Parameter to enable Schema Evolution.
spark.sql("SET spark.databricks.delta.schema.autoMerge.enabled = true")
staging_table_1_data
.writeStream
.format("delta")
.option("mergeSchema", "true") # Option to enable new schema merges.
.option("checkpointLocation", target_checkpoint)
.foreachBatch(upsertToDeltaDF)
.trigger(once=True) # Enable continuous streaming if required.
.outputMode("update")
.start()
We can enhance the existing batch jobs to support near-real-time data streaming by changing the trigger parameter of readstream from (Trigger.Once) to (Trigger.Continuous).
Some of the key approaches to the existing architecture include:
- Primary keys for each table are populated and maintained in a separate S3 config file through a separate semi-automated process.
- Automatically create tables if they do not exist using the PySpark code (during Stage1 and Stage2 of the processing service).
- Leveraging Auto Loaders at each stage of our pipeline to ensure compatibility with both streaming and batch processing requirements. This approach enables us to seamlessly process data in either mode, depending on the specific needs of the business.
- Ability to perform full refresh of an existing table using an input argument.
Up to now, we have discussed the processing layer of our data architecture. We will now move on to the orchestration layer. The orchestration layer is a critical component that manages the interactions between a variety of data engineering processes, including Amazon MWAA (Airflow DAGS), , and parameterized Databricks Jobs.
To facilitate this, we use Amazon MWAA as the main orchestration framework for authoring, scheduling and monitoring workflows for a variety of Exchange, Transfer, Load (ETL) processes, and Databricks Workflows to orchestrate services specific to Lakehouse. These services include Databricks Jobs, job run monitoring, and job concurrency management. By leveraging these tools, we are able to efficiently manage and streamline our data engineering processes.
In designing the GDDL architecture, we implemented automatic scaling of Amazon MWAA based on demand for dynamic DAG creation, using the metadata definition file stored in S3. This metadata includes information such as the size, priority, and primary keys of the tables, which are used to invoke specific Databricks workflows to optimize compute costs and meet SLAs.
When needing to onboard new tables, teams like Machine Learning can self-serve by adding the metadata definitions themselves. In order to meet the platform needs of new table additions, concurrent DAG and task runs are scaled out by periodically adjusting parameters related to scaling in Airflow, such as DAG_CONCURRENCY and PARALLELISM. This approach enables us to efficiently manage resources and meet performance requirements in a cost-effective manner.
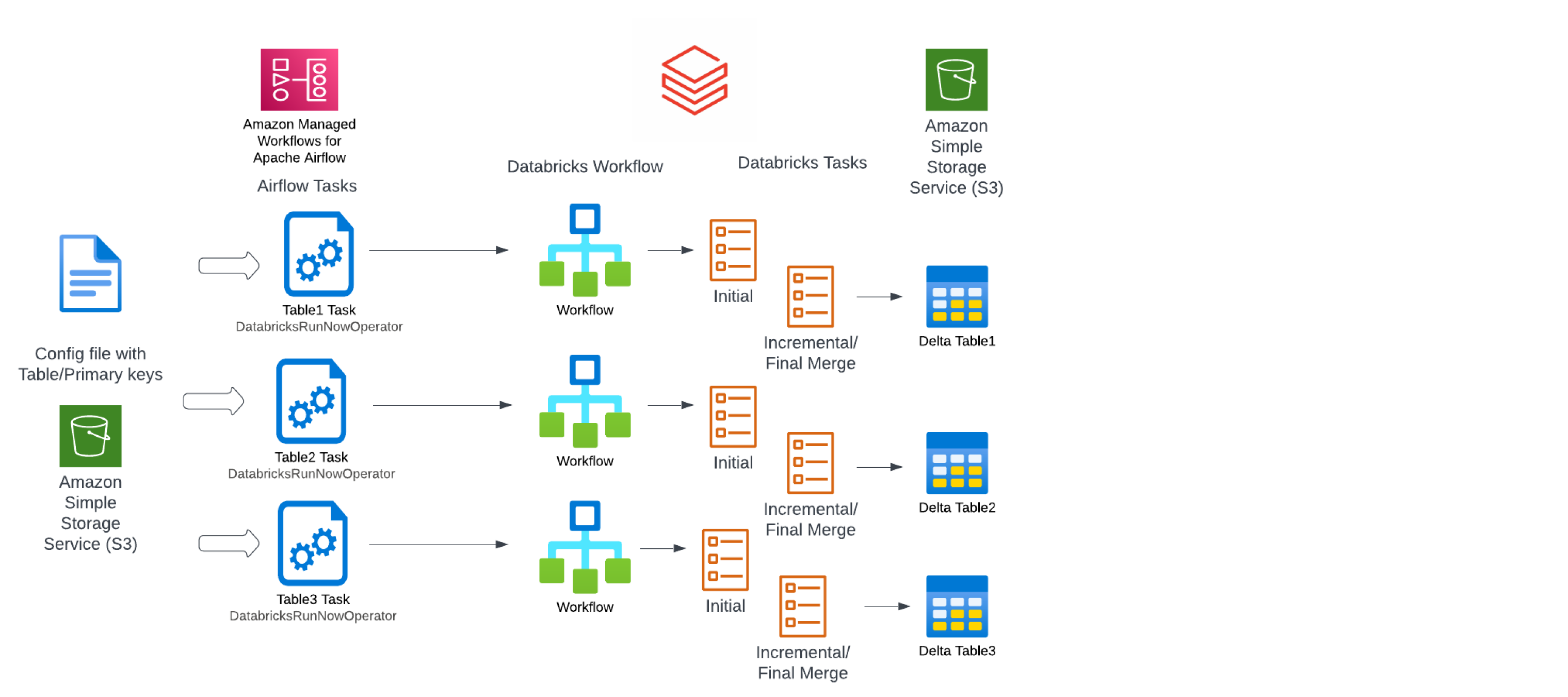 Figure 4: Incremental ingestion of data using Databricks Workflows into delta tables.
Figure 4: Incremental ingestion of data using Databricks Workflows into delta tables.
Data is loaded chronologically to the Lakehouse by executing the initial and incremental tasks of Databricks workflows. Job concurrency limits are set to 1,000 in order to perform large-scale parallel production data loads. Built-in monitoring capabilities of Databricks Workflows, especially the matrix view, is being used extensively by the team to constantly observe job run times and act upon them when appropriate.
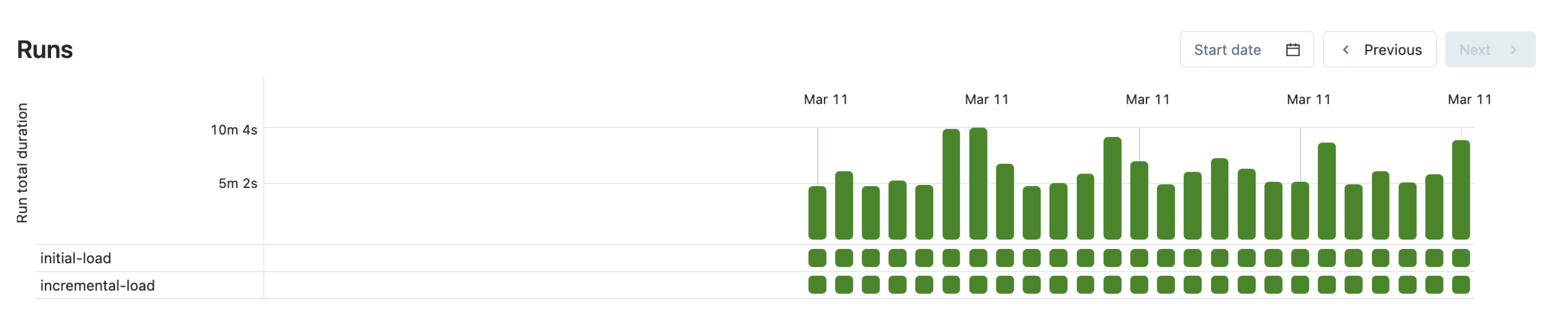 Figure 5: Visual of job monitoring matrix in Databricks.
Figure 5: Visual of job monitoring matrix in Databricks.
Future Considerations
As we continue to iteratively improve our core capabilities and ensure the GDDL framework meet the highest standards, we have identified several enhancements that we plan to implement:
- Given the success of this overall framework, the team will be adapting and extending the GDDL architecture to other source systems, such as NoSQL databases and messaging systems.
- Leverage for our Databricks Workflows to take advantage of its built-in data quality controls and operational efficiencies.
- Integrate workflow metrics with observability solutions like Datadog for proactive monitoring.
Conclusion
To meet the technical challenges and business requirements of our expanding data universe, Gemini developed the GDDL architecture using powerful features and services of AWS and Databricks such as MWAA, DMS, and Databricks Workflows. This architecture ensures automatic scaling, structural evolution, and efficient replication and loading of data into our Lakehouse within defined SLAs.
As a result, our team benefits from a highly efficient data replication process that is scalable, supports schema evolution, and is both config-driven and automated. This approach allows us to set up data ingestion for new databases within minutes, saving significant time and resources that would otherwise be required to develop data pipelines manually from scratch. By using a configuration-driven approach to choose batch run times, we have also been able to significantly reduce compute costs involved in our ETL processes.
Given the success of the GDDL architecture, we have adapted it across the Gemini organization for seamless data replication and ingestion, and we are looking forward to continuing to iterate and improve on our processes.
Gemini Analytics Team
About the authors:
Keerthivasan Santhanakrishnan is a Senior Data Engineer at Gemini with a focus on the architecture, design, and implementation of real-time streaming, data ingestion, and data platform solutions using big data and cloud computing technologies.
Anil Kumar Kovvuri is a Principal Data Engineer at Gemini. He is responsible for leading the overall Data Lake architecture and currently oversees blockchain analytics at Gemini.
Sriram Rajappa is the GM for Gemini Analytics. Apart from being in charge of running the data program at Gemini, Sriram mentors, encourages, and guides the team on overall big data and analytics architecture.
Decentralization and transparency are central to crypto's ethos. At Gemini, we want to contribute to greater understanding and knowledge around fast-paced technical developments in crypto and help further drive innovation in our industry. In this blog, we are proud to provide a glimpse of a data engineering architecture developed by our engineers as we continue to build the future of crypto.
RELATED ARTICLES

MARKETS
JUL 16, 2026
Zcash Mounts Summer Rally, Ethereum Rebounds, and Bitcoin Tests $65,000 Again

MARKETS
JUL 14, 2026
Gemini Predicted: Bitcoin Pushes Back Toward $65,000, LeBron Plots Next Move, and Oil Prices Rise Again

MARKETS
JUL 09, 2026